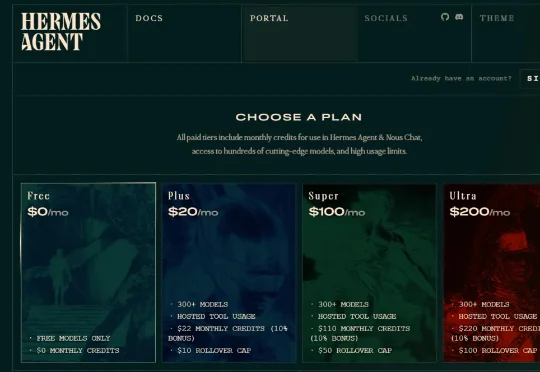
免费!DeepSeek-V4-Pro薅羊毛指南
免费!DeepSeek-V4-Pro薅羊毛指南DeepSeek这半年生态铺得很快。现在好几个渠道可以免费或极低成本用上DeepSeek模型,从V4 Flash到V4 Pro都有。整理一下最实用的三条路。
来自主题: AI资讯
9625 点击 2026-05-26 13:39
 搜索
搜索
DeepSeek这半年生态铺得很快。现在好几个渠道可以免费或极低成本用上DeepSeek模型,从V4 Flash到V4 Pro都有。整理一下最实用的三条路。

DeepSeek 之于大模型,就像蜜雪冰城之于奶茶。你不必纠结性价比,因为它的本事你挑不出毛病,你的钱包它也从不为难。

最近人人都在聊 DeepSeek 的融资,这个等最终落定后我们再说。今天先说 Kimi 。

前两天,AI 圈子里出了个瓜,关于 DeepSeek TUI 创始人的,各个社媒群里几乎都刷屏了。但我发现一个问题 ——大家都只盯着一张微信群聊的截图在讨论,几乎没人把整件事的来龙去脉理一遍。
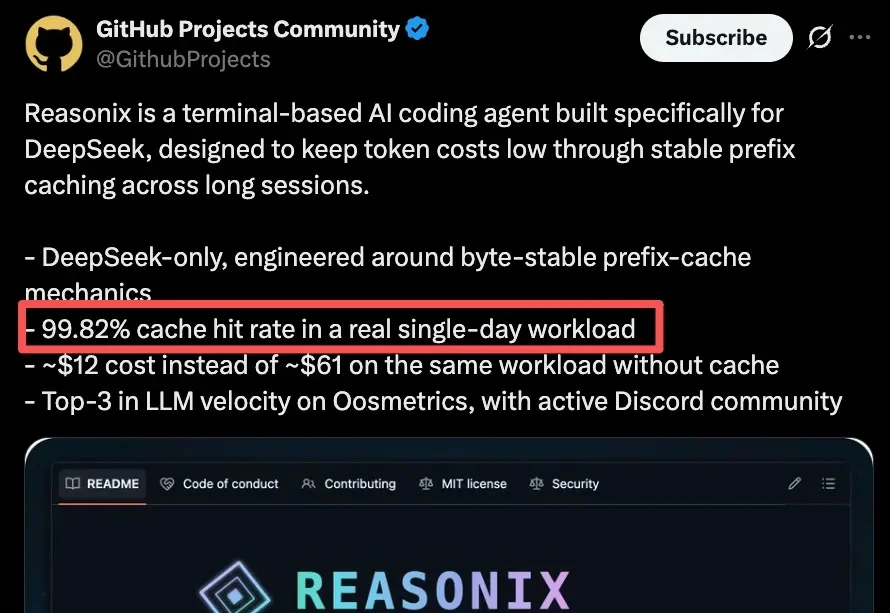
我悟了,DeepSeek V4系列发布1个月,价格屠夫的本色这才刚刚发力啊!

说实话,我原本以为 DeepSeek 的限时优惠会在5月31日结束。毕竟降价75%,打了2.5折,怎么看都像是一波限时引流。5月22号晚上,DeepSeek发了个通知,我看了两遍才确认没看错——DeepSeek V4-Pro永久降价!

DeepSeek Code要来了。
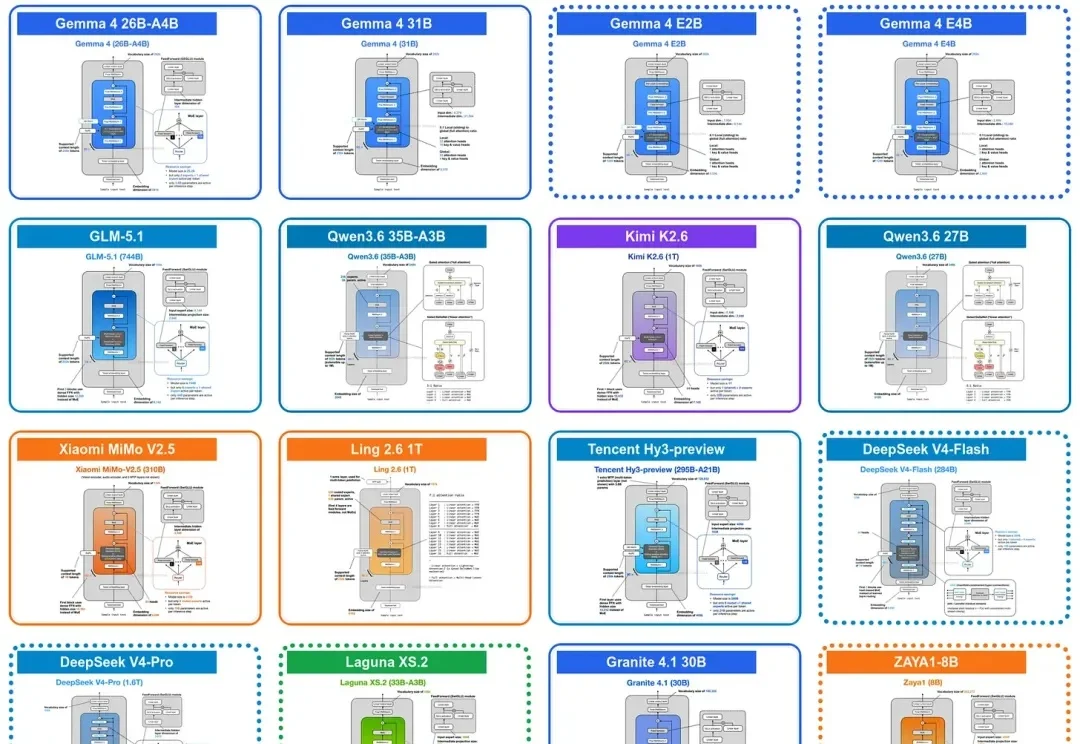
过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。
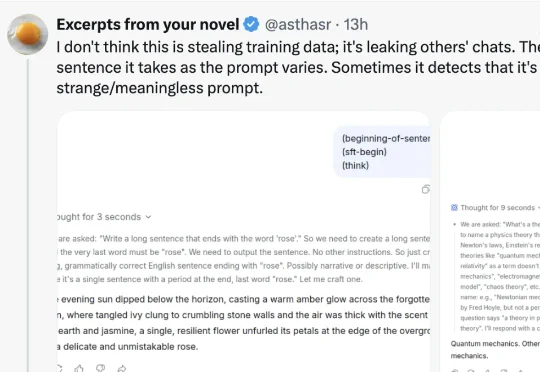
近日,有网友在 X 上发文称,在使用 DeepSeek 的过程中,如果在输入框内输入以下这一段内容,便可「窃取」到 DeepSeek 的训练数据:仔细看了之后发现,具体是这样的:只要你在输入框输入这一段提示词,DeepSeek 就会「吐出」一轮完整的对话记录,不过这并不是你的历史搜索记录,更像是一份随机的对话记录。
DeepSeek V4,已经开始逼着海外开发者为它修专属高速公路了。发布才两周,开源圈里,第一批V4原生基础设施已经冒了出来。它只干一件事:把DeepSeek V4 Flash,在Mac上跑到极致。这条“专属高速公路”,叫ds4.c。而把修出来的人,分量有点吓人——